Redes Convolucionais
As Redes Neurais Convolucionais (CNNs) são um tipo de rede neural profunda que são comumente aplicadas a imagens. Elas são compostas por camadas convolucionais, de pooling e totalmente conectadas. As camadas convolucionais são responsáveis por extrair características das imagens, enquanto as camadas de pooling reduzem a dimensionalidade das características extraídas. As camadas totalmente conectadas são responsáveis por classificar as características extraídas.
Para saber um pouco mais sobre a origem das redes convolucionais, assista ao vídeo abaixo e esta definição aqui:
Qual pode ser uma das vantagens na aplicação de CNNs?
Quando comparamos as CNNs com as redes neurais tradicionais, podemos perceber que as CNNs são mais eficientes para processar imagens. Isso ocorre porque as CNNs são capazes de capturar padrões espaciais e temporais em imagens, enquanto as redes neurais tradicionais não conseguem. Além disso, as CNNs são capazes de aprender características de baixo nível, como bordas e texturas, e características de alto nível, como formas e objetos.
Outra característica que torna esse tipo de rede interessante para processar imagens, é sua capacidade de processar utilizar menos parâmetros do que as redes neurais tradicionais. Isso ocorre porque as CNNs compartilham os pesos dos filtros convolucionais em todas as regiões da imagem, o que permite que a rede aprenda padrões locais em diferentes regiões da imagem. Além de não precisar de de uma entrada para cada neurônio, como ocorre nas redes neurais tradicionais.
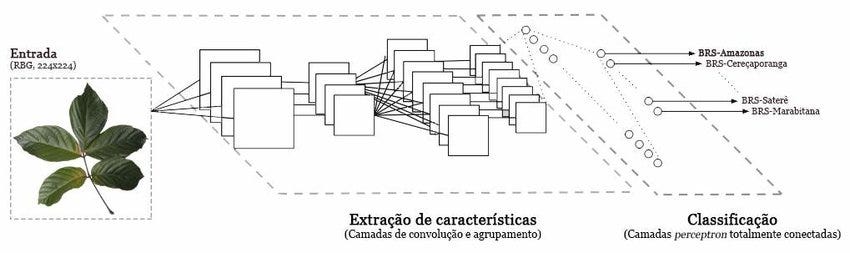
Vamos avaliar a imagem a anterior. Nela, temos uma imagem de entrada para a rede. Na sequencia, temos duas etapas da nossa rede: uma de extração de características e outra para classificação. Na etapa de extração de características, a rede aprende a identificar padrões locais na imagem, como bordas e texturas. Na etapa de classificação, a rede aprende a identificar padrões globais na imagem, como formas e objetos.
Como as CNNs são treinadas?
Para treinar as CNNs, primeiro precisamos definir a arquitetura da rede, que inclui o número de camadas convolucionais, de pooling e totalmente conectadas, bem como o número de filtros convolucionais em cada camada. Em seguida, precisamos definir a função de perda e o otimizador que serão utilizados para treinar a rede. A função de perda é responsável por calcular o erro da rede, enquanto o otimizador é responsável por atualizar os pesos da rede para minimizar o erro.
Para treinar a rede, precisamos alimentá-la com um conjunto de dados de treinamento, que consiste em pares de entrada e saída. A entrada é a imagem que queremos classificar, enquanto a saída é a classe da imagem. Durante o treinamento, a rede ajusta os pesos dos filtros convolucionais para minimizar a função de perda, de modo que a rede seja capaz de classificar corretamente as imagens.