CNN LeNet
O modelo de introdução do uso de redes neurais convolucionais foi a LeNet, desenvolvida por Yann LeCun em 1998. A LeNet foi projetada para reconhecimento de dígitos manuscritos e foi a primeira rede a demonstrar sucesso em tarefas de reconhecimento de imagens. Ela é composta por 7 camadas, sendo 3 camadas convolucionais e 2 camadas de pooling. A arquitetura da LeNet é mostrada na figura abaixo:
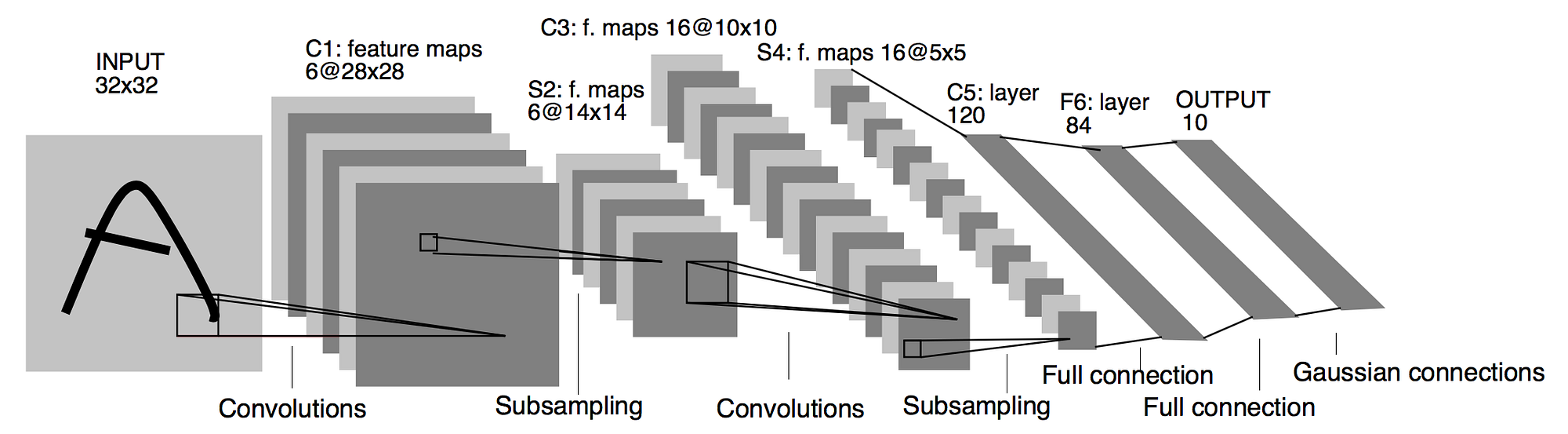
A primeira camada convolucional tem 6 filtros de tamanho 5x5, a segunda camada convolucional tem 16 filtros de tamanho 5x5 e a terceira camada convolucional tem 120 filtros de tamanho 5x5. As camadas de pooling são do tipo max pooling e são aplicadas após as camadas convolucionais. A LeNet também possui 2 camadas totalmente conectadas, uma com 84 neurônios e outra com 10 neurônios, que correspondem às 10 classes do dataset MNIST.
O trabalho completo de Yann LeCun sobre a LeNet pode ser encontrado aqui. E aqui pode ser encontrada uma analise detalhada sobre cada uma das camadas e a aplicação do algoritmo.
Dataset MNIST
O dataset MNIST é um dos mais utilizados para treinar e testar algoritmos de reconhecimento de dígitos manuscritos. Ele é composto por 60.000 imagens de treinamento e 10.000 imagens de teste, cada uma com dimensões de 28x28 pixels. As imagens são em escala de cinza e as classes são os dígitos de 0 a 9.

O dataset MNIST pode ser carregado diretamente de diversas bibliotecas de deep learning, como o TensorFlow e o Keras. Para saber mais sobre o dataset MNIST, acesse aqui. Recomendo a leitura da descrição realizada pelo Ultralytics sobre o dataset.
Implementação da LeNet com Keras
A implementação da LeNet com Keras é relativamente simples, pois a biblioteca já possui implementações de camadas convolucionais, de pooling e totalmente conectadas. Vamos primeiro criar um ambiente virtual e instalar as bibliotecas necessárias:
python3 -m venv venv
source venv/bin/activate
python3 -m pip install keras numpy matplotlib tensorflow jupyterlab np_utils opencv-python
Agora vamos criar o notebook para implementar a LeNet com Keras:
# Trabalho com o MNIST - numeros manuscritos
from keras.datasets import mnist
# Carregando o dataset separando os dados de treino e de teste
(x_treino, y_treino), (x_teste, y_teste) = mnist.load_data()
# Permite imprimir dentro do notebook Python
import matplotlib.pyplot as plt
%matplotlib inline
# Exemplo de um dado do dataset
plt.imshow(x_treino[4], cmap='gray_r')
# Trazendo a função `to_categorical` para transformar os labels em one-hot encoding
from keras.utils import to_categorical
y_treino_cat = to_categorical(y_treino)
y_teste_cat = to_categorical(y_teste)
# Verificação da saída one-hot encoding
print(y_treino[0]) #Valor da classe
print(y_treino_cat[0]) #Representação onehot
# Normalização dos dados de entrada
x_treino_norm = x_treino/x_treino.max()
x_teste_norm = x_teste/x_teste.max()
# Reshape dos dados de entrada para adicionar o canal de cor
x_treino = x_treino.reshape(len(x_treino), 28, 28, 1)
x_treino_norm = x_treino_norm.reshape(len(x_treino_norm), 28, 28, 1)
x_teste = x_teste.reshape(len(x_teste), 28, 28, 1)
x_teste_norm = x_teste_norm.reshape(len(x_teste_norm), 28, 28, 1)
# Importação das bibliotecas necessárias para treinar a rede
#Modelo da rede
from keras.models import Sequential
#Camadas que serão utilizadas
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten, Dropout
# Criação do modelo LeNet5
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), padding='same', activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPool2D(strides=2))
model.add(Conv2D(filters=48, kernel_size=(5,5), padding='valid', activation='relu'))
model.add(MaxPool2D(strides=2))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(84, activation='relu'))
model.add(Dense(10, activation='softmax'))
# Constroi o modelo
model.build()
# Exibe um resumo do modelo
model.summary()
#Compila o modelo
adam = Adam()
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer=adam)
# Realiza o treinamento do modelo
historico = modelo.fit(x_treino_norm, y_treino_cat, epochs=5, validation_split=0.2)
# Exibe o histórico do treinamento
# Graficos de perda e acurácia
# Acurácia
plt.plot(historico.history['accuracy'])
plt.plot(historico.history['val_accuracy'])
plt.legend(['treino', 'validacao'])
plt.xlabel('epocas')
plt.ylabel('acuracia')
# Perda
plt.plot(historico.history['loss'])
plt.plot(historico.history['val_loss'])
plt.legend(['treino', 'validacao'])
plt.xlabel('epocas')
plt.ylabel('perda')
# Salva o modelo
model.save('modelo_mnist.h5')
# Carrega o modelo
from tensorflow.keras.models import load_model
modelo_2 = load_model('modelo_mnist.h5')
# Realiza uma predição com o modelo
predicao = model.predict(x_teste_norm[0].reshape(1, 28, 28, 1))
print(predicao)
# Exibe a classe com a maior probabilidade de ser a correta da predição
import numpy as np
np.argmax(predicao)
Vamos compreender alguns conceitos acima:
Conv2D: camada convolucional que aplica um filtro convolucional na imagem de entrada.MaxPool2D: camada de pooling que reduz a dimensionalidade das características extraídas.Flatten: camada que transforma a saída das camadas convolucionais em um vetor para ser utilizado nas camadas totalmente conectadas.Dense: camada totalmente conectada que classifica as características extraídas.Dropout: camada que previne o overfitting ao desativar aleatoriamente alguns neurônios durante o treinamento.Adam: otimizador que ajusta os pesos da rede durante o treinamento.categorical_crossentropy: função de perda que calcula o erro da rede durante o treinamento. A definição deCategotical Crossentropypode ser dada como: Categorical Cross Entropy is also known as Softmax Loss. It’s a softmax activation plus a Cross-Entropy loss used for multiclass classification. Using this loss, we can train a Convolutional Neural Network to output a probability over the N classes for each image. In multiclass classification, the raw outputs of the neural network are passed through the softmax activation, which then outputs a vector of predicted probabilities over the input classes. In the specific (and usual) case of multi-class classification, the labels are one-hot, so only the positive class keeps its term in the loss.