Hash tables (e o dicionário de Python)
Falamos de arrays e estruturas de dados "elementares", falamos de estruturas mais complexas que foram feitas para crescer de forma indefinida, mas agora está na hora de falar de um tipo de estrutura de dados muito utilizada quando queremos otimizar a performance de busca de elementos, a hash table.
Por quê a hash table é boa?
Bom, lembrando do conceito de complexidade algoritmica utilizando a notação big O, temos alguns casos bem comuns:

Qual é o melhor caso possível? O(1)
Qual é a complexidade algoritmica de buscas em uma hash table? O(1)
Interessante, né? Para começar a entender como as hash tables fazem essa mágica, vamos começar falando sobre o algoritmo de hash.
1. O algoritmo de hash
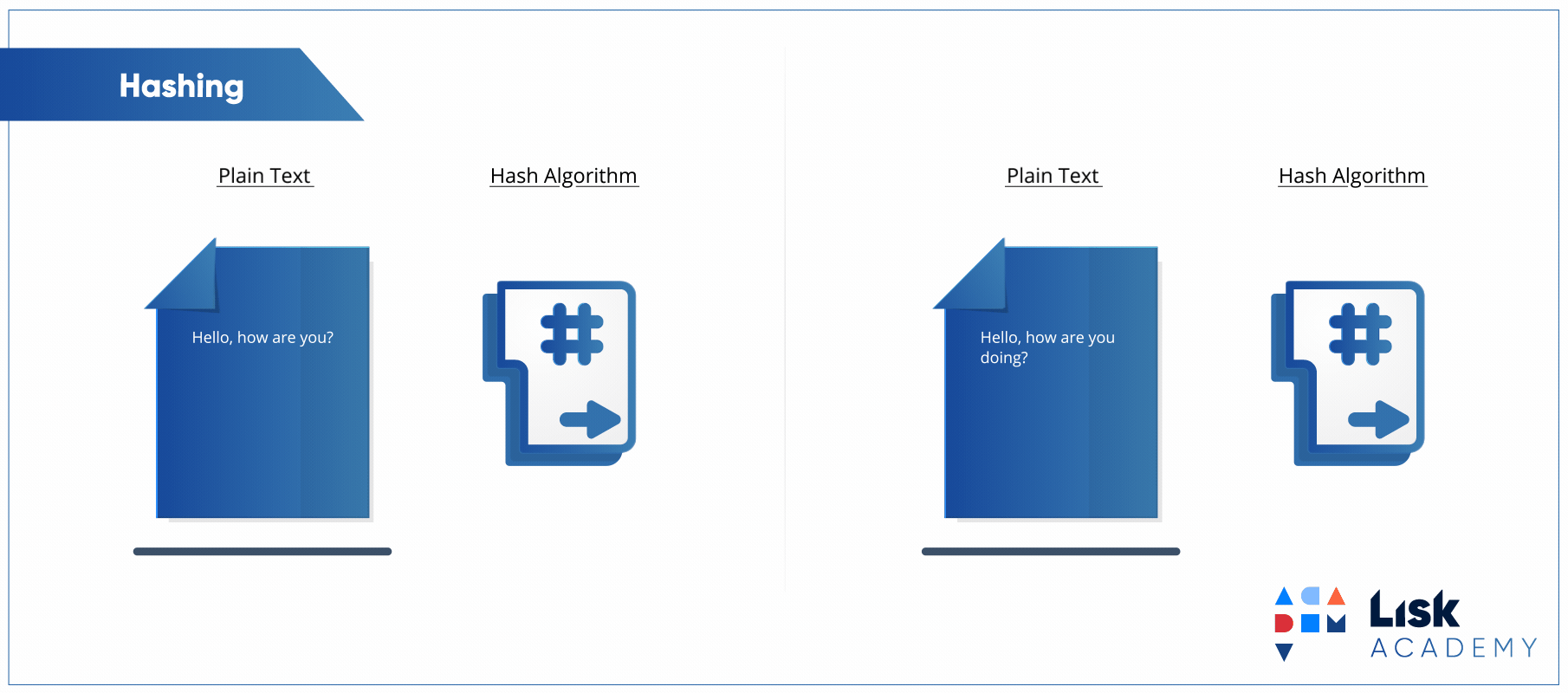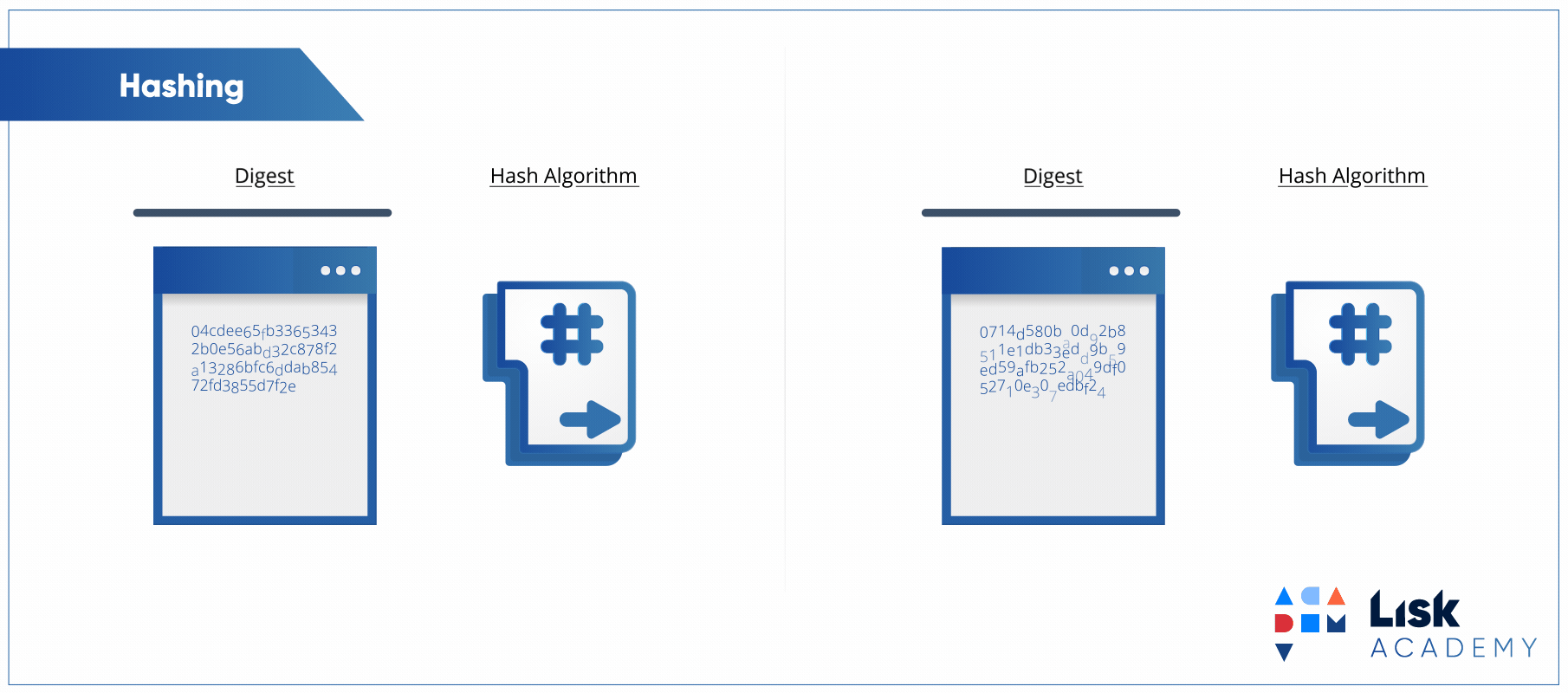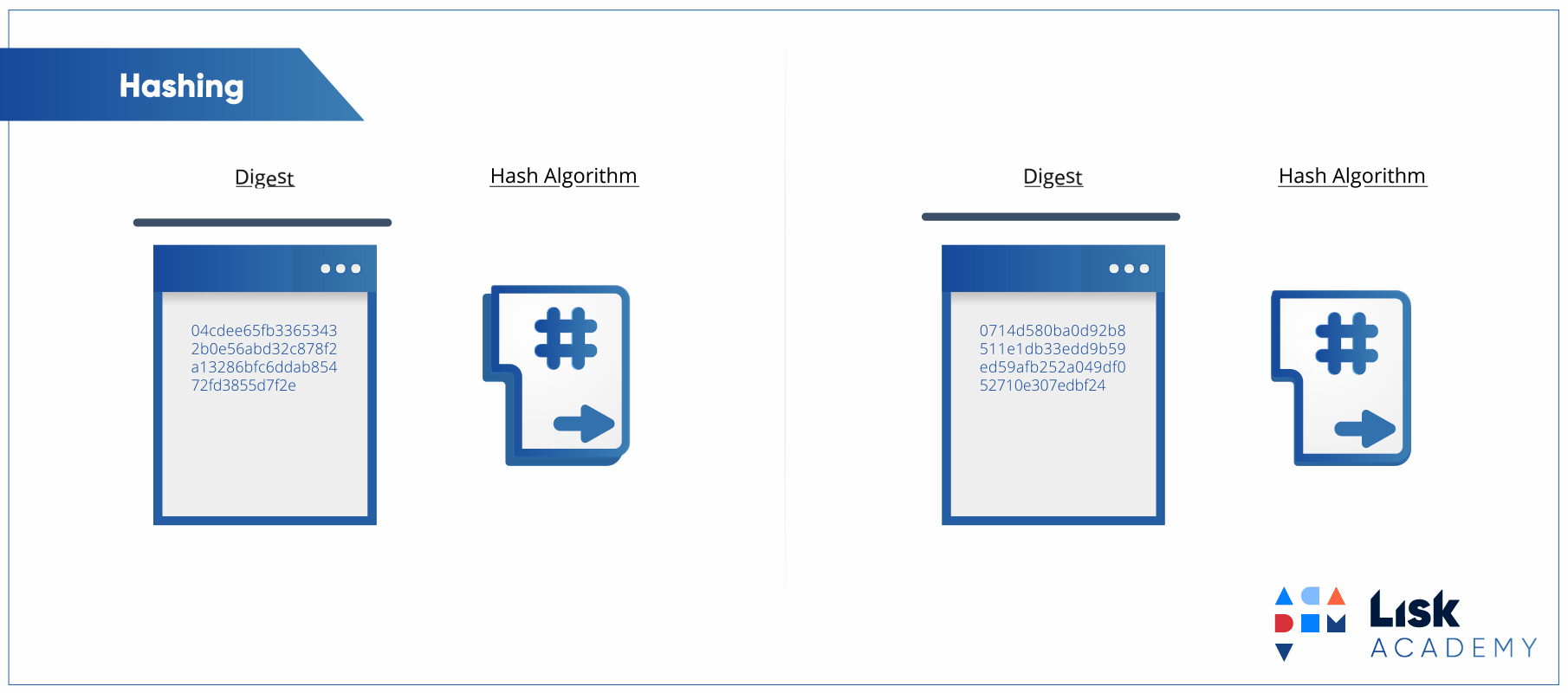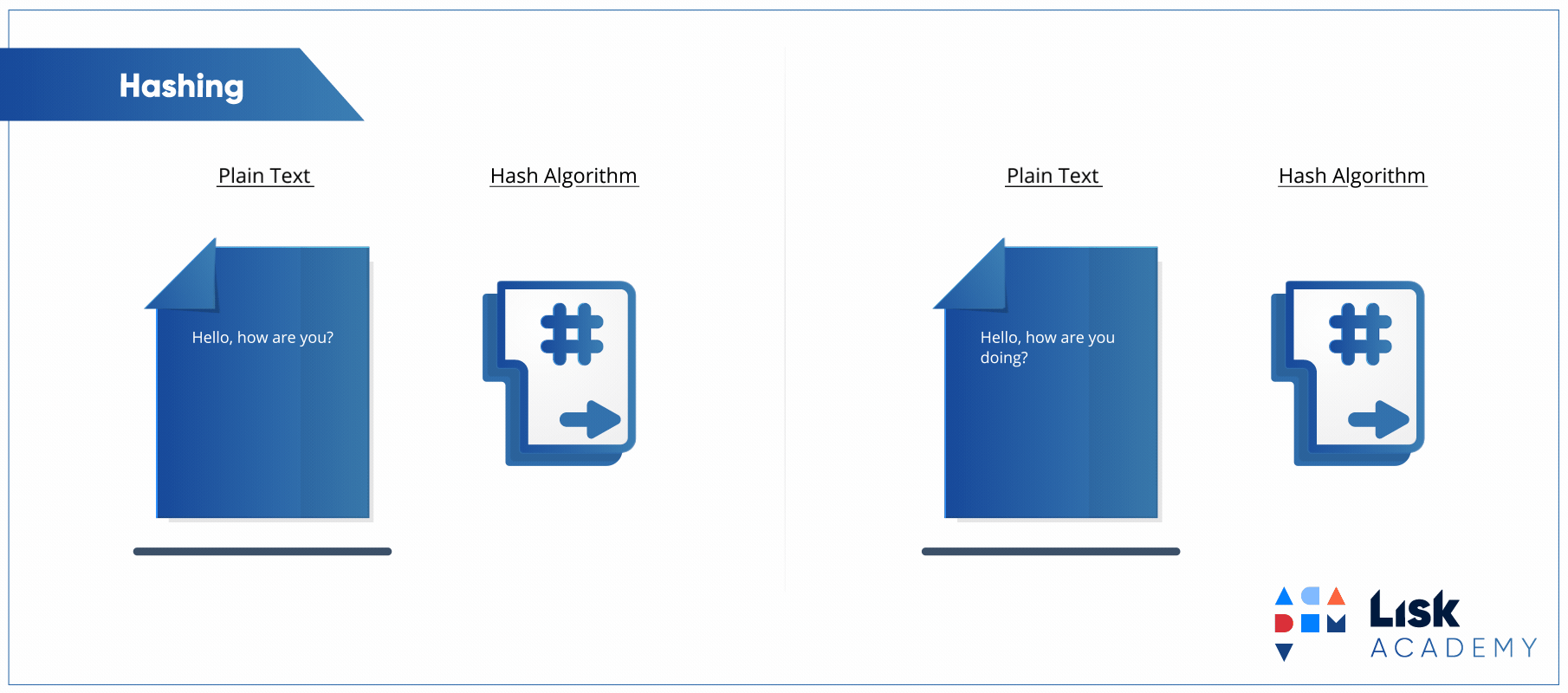
Para explicar o que é um algoritmo de hash vou apresentar para vocês um clássico do canal Computerphile:
Embora o vídeo seja completamente focado no uso de hashes para segurança, os conceitos apresentados são mapeáveis para o hash utilizado no hash table, pois é exatamente o mesmo conceito. A ideia é converter um texto, ou chave, em um valor numérico único (ou quase sempre único).
Tá, mas o que isso tem a ver com hash tables e acesso a elementos com complexidade O(1)? Tudo, na verdade. Se o valor numérico é único, o que acontece se usarmos esse valor como o índice de um array? O resultado é que criamos uma hash table.
2. Hash table
Ainda não entendeu a importância do que falei logo acima? Sem problemas, veja esse vídeo do canal Computer Science que vai te ajudar:
O conceito, no fundo, é super simples:
- Defina uma função de hash que funcione para o seu tipo de chave e possivelmente limite colisões;
- Estruture seus valores de modo que o hash da chave seja o índice para encontrar os valores;
- Profit.

O que nos resta? Nos resta ver uma implementação bastante simplória de um hash table em C. Note que eu não estou nem tratando colisões nessa implementação.
#include <stdio.h>
#include <string.h>
#define TABLE_SIZE 100
typedef struct {
char* key;
int value;
} Entry;
Entry hashTable[TABLE_SIZE];
// Função de hash simples
unsigned int hash(const char *key) {
unsigned long int value = 0;
unsigned int i = 0;
unsigned int key_len = strlen(key);
// Convertendo a chave para um inteiro
for (; i < key_len; ++i) {
value = value * 37 + key[i];
}
// Garantir que o valor esteja dentro dos limites da tabela
value = value % TABLE_SIZE;
return value;
}
// Inserir chave-valor na hash table
void insert(char* key, int value) {
unsigned int index = hash(key);
hashTable[index].key = key;
hashTable[index].value = value;
}
// Buscar um valor pela chave na hash table
int search(char* key) {
unsigned int index = hash(key);
if (strcmp(hashTable[index].key, key) == 0) {
return hashTable[index].value;
} else {
return -1; // Assume-se que -1 indica "não encontrado"
}
}
int main() {
char* keys[] = {"key1", "key2", "key3", "key4"};
int values[] = {10, 20, 30, 40};
for (int i = 0; i < 4; i++) {
insert(keys[i], values[i]);
}
// Buscando valores
printf("O valor de 'key2' é %d\n", search("key2"));
printf("O valor de 'key4' é %d\n", search("key4"));
return 0;
}
3. Dicionários e hash map (e o Javascript)
O que os dicionários de Python tem a ver com hash tables? Vamos pensar nas características de um dicionário:
- Ele armazena dados no formato
{chave:valor}; - Ele não garante a ordem dos dados inseridos;
- De alguma forma ele é consideravelmente mais performático que as listas;
Ora, Scooby, acho que temos nosso vilão:

Sim, o dicionário de Python é só uma hash table de roupa social. Vamos dar uma enfeitada no código que fizemos anteriormente para ficar mais parecido com um dicionário? O que vamos mudar?
- Adicionar um tratamento de colisão utilizando listas ligadas;
- Adicionar funcionalidades básicas como inserção de dados e buscas; e
- Adicionar a capacidade de armazenar tipos de dados distintos no valor.
Ainda estamos muito longe do dicionário de Python, mas aqui está a nossa versão mais pobrinha do dicionário em C:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define TABLE_SIZE 10
typedef enum {
INT, FLOAT, CHAR
} ValueType;
typedef struct {
ValueType type;
union {
int i;
float f;
char c;
} data;
} Value;
typedef struct node {
char* key;
Value value;
struct node* next;
} Node;
Node* hashTable[TABLE_SIZE];
// Função de hash
unsigned int hash(const char *key) {
unsigned long int value = 0;
unsigned int i = 0;
unsigned int key_len = strlen(key);
for (; i < key_len; ++i) {
value = value * 37 + key[i];
}
value = value % TABLE_SIZE;
return value;
}
// Inserir ou atualizar um par chave-valor no hash map
void insert(char* key, Value value) {
unsigned int index = hash(key);
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->key = strdup(key);
newNode->value = value;
newNode->next = NULL;
if (hashTable[index] == NULL) {
hashTable[index] = newNode;
} else {
Node* current = hashTable[index];
while (current->next != NULL && strcmp(current->key, key) != 0) {
current = current->next;
}
if (strcmp(current->key, key) == 0) {
current->value = value;
free(newNode->key);
free(newNode);
} else {
current->next = newNode;
}
}
}
// Buscar um valor pela chave
Value search(char* key) {
unsigned int index = hash(key);
Node* current = hashTable[index];
while (current != NULL) {
if (strcmp(current->key, key) == 0) {
return current->value;
}
current = current->next;
}
// Retornar um tipo especial indicando não encontrado
Value notFound;
notFound.type = INT; // Default type
notFound.data.i = -1; // Indicando não encontrado
return notFound;
}
// Função para imprimir o hash map
void printValue(Value value) {
switch(value.type) {
case INT: printf("%d", value.data.i); break;
case FLOAT: printf("%f", value.data.f); break;
case CHAR: printf("%c", value.data.c); break;
}
}
void printHashMap() {
for (int i = 0; i < TABLE_SIZE; ++i) {
Node* current = hashTable[i];
if (current == NULL) {
printf("Index %d: (null)\n", i);
} else {
printf("Index %d:", i);
while (current != NULL) {
printf(" (%s: ", current->key);
printValue(current->value);
printf(")");
current = current->next;
}
printf("\n");
}
}
}
int main() {
Value intValue = {.type = INT, .data.i = 100};
Value floatValue = {.type = FLOAT, .data.f = 123.456};
Value charValue = {.type = CHAR, .data.c = 'A'};
insert("key1", intValue);
insert("key2", floatValue);
insert("key3", charValue);
printf("Value for 'key1': ");
printValue(search("key1"));
printf("\nValue for 'key2': ");
printValue(search("key2"));
printf("\nValue for 'key3': ");
printValue(search("key3"));
printf("\n");
printHashMap(); // Mostrar o estado do hash map
return 0;
}
mas, mas, mas... e o Javascript?
Eu só vou deixar esse gif aqui e o trabalho de comprovar se isso é verdade ou não fica como lição de casa:
