Bases de dados NoSQL
1. SQL vs NoSQL
Bancos de dados SQL (Structured Query Language) e NoSQL (Not Only SQL) são dois tipos principais de sistemas de gerenciamento de banco de dados que são usados para armazenar e gerenciar dados. A principal diferença entre esses dois tipos de banco de dados é a existência de relações entre os dados armazenados. Os bancos NoSQL não criam relações entre os dados. Em termos práticos, essa troca impacta os seguintes aspectos do banco de dados:
- Modelagem de dados
- Escalabilidade
- Transações
- Consultas
1.1. Modelagem de dados
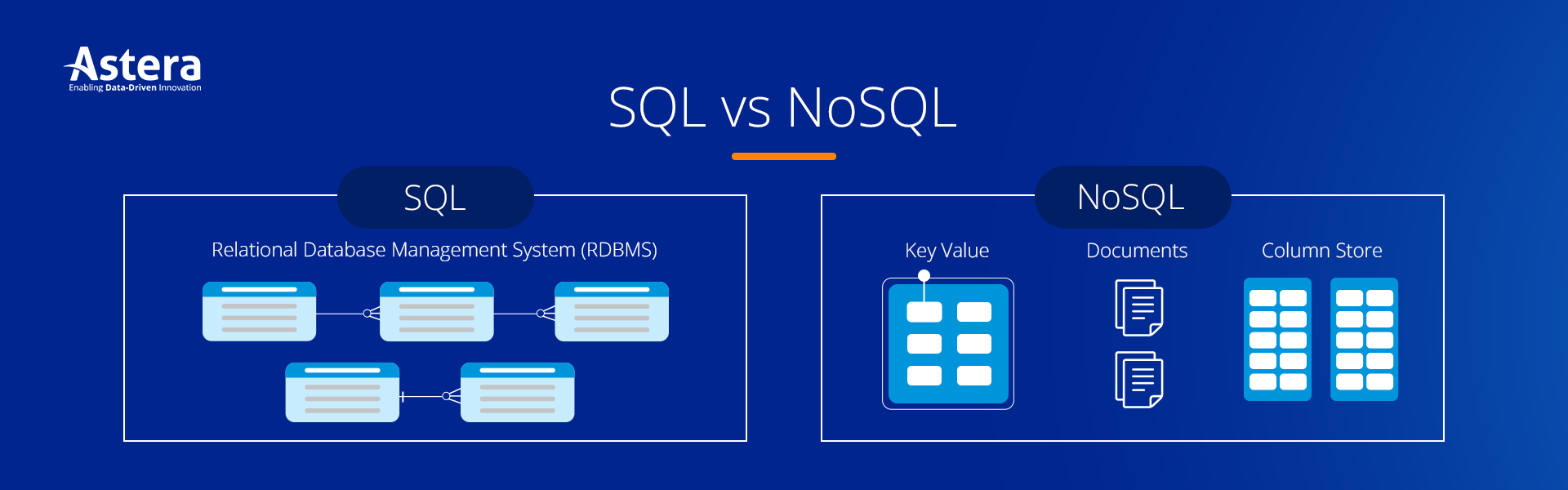
Os bancos SQL utilizam um modelo de dados relacional, onde os dados são organizados em tabelas com linhas e colunas. As tabelas são relacionadas entre si através de chaves estrangeiras. Este modelo é ideal para dados estruturados e relações complexas. O seu esquema é rígido, o que significa que a estrutura das tabelas e os tipos de dados das colunas devem ser definidos antes de inserir os dados. Alterações no esquema podem ser trabalhosas.
Em comparação, os bancos NoSQL adotam uma variedade de modelos de dados, incluindo documentos (MongoDB), chave-valor (Redis), colunas largas (Cassandra) e grafos (Neo4j). Esses modelos são mais flexíveis e adequados para armazenar dados não estruturados ou semi-estruturados. Em termos gerais, os bancos NoSQL apresentam os dados em um formato livre e há algum mecanismo de indexação para tornar as operações de leitura mais performáticas. Bancos NoSQL apresentam esquemas flexíveis ou nenhum esquema, o que significa que costuma ser muito simples adicionar novos campos.
1.2. Escalabilidade
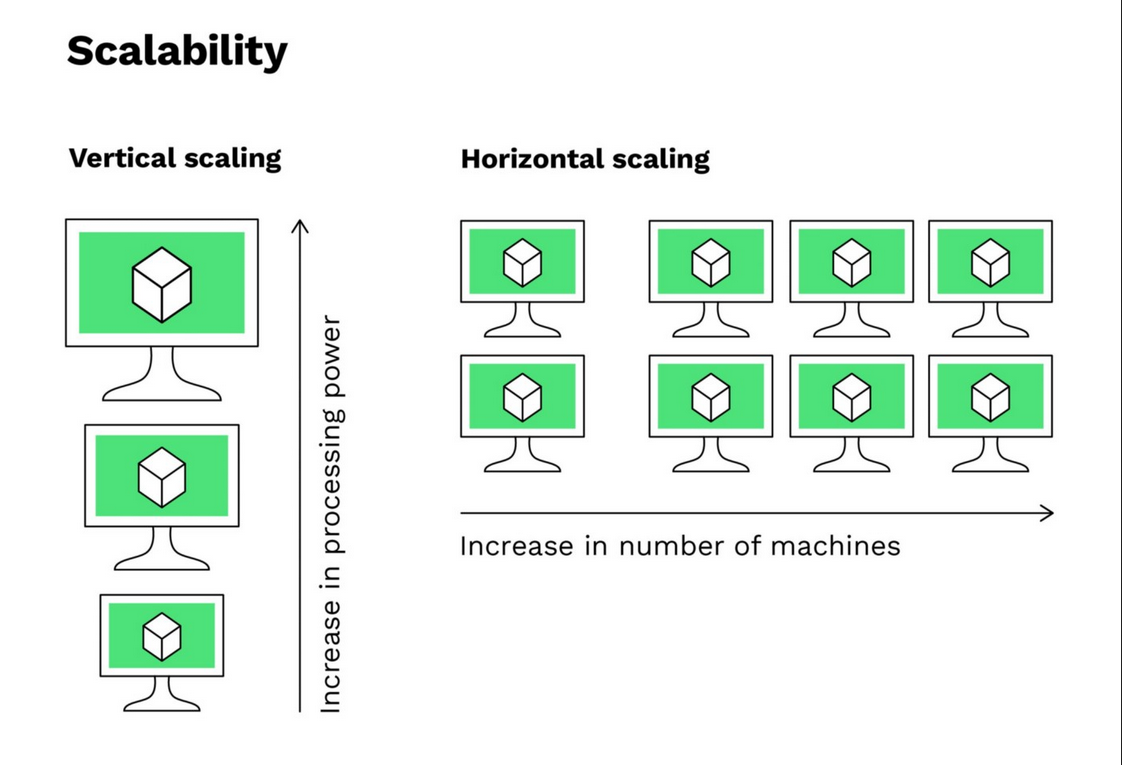
Por existir relações entre os dados aramzenados, os bancos SQL incorrem comumente sobre o problema de uma operação futura depender de uma operação anterior. O efeito prático desse problema é que é muito difícil paralelizar consultar SQL. Com efeito, o tipo de escalabilidade possível para esse tipo de banco de dados é a vertical (mais poder de processamento para um mesmo thread). É notório que esse tipo de escalabilidade tem um aumento de custo exponencial conforme aumentamos o tamanho do problema.
Enquanto isso, os bancos NoSQL gozam da possibilidade de escalar de forma horizontal, pois suas consultas não tem relação nenhuma uma com a outra. É trivial, inclusive, espalhar um banco NoSQL em diversos servidores diferentes.
1.4. Transações

Os bancos SQL têm como o padrão de ouro transações ACID, enquanto a maioria dos bancos NoSQL trabalham com transações BASIC, mas, o que isso significa?
1.4.1. ACID vs BASE
ACID e BASE são dois conjuntos de propriedades que garantem a confiabilidade das transações em sistemas de banco de dados. Eles representam abordagens diferentes para lidar com a consistência e a disponibilidade dos dados.
ACID (Atomicidade, Consistência, Isolamento, Durabilidade):
- Atomicidade: Garante que todas as operações em uma transação sejam concluídas com sucesso ou nenhuma seja aplicada. É tudo ou nada.
- Consistência: Assegura que uma transação leve o banco de dados de um estado consistente para outro estado consistente, mantendo a integridade dos dados.
- Isolamento: Garante que as transações sejam executadas de forma isolada umas das outras, evitando interferências e garantindo que os resultados sejam os mesmos como se as transações fossem executadas sequencialmente.
- Durabilidade: Uma vez que uma transação foi confirmada, ela permanece gravada no banco de dados, mesmo em caso de falha do sistema ou queda de energia.
Os sistemas de banco de dados que seguem o modelo ACID, como os bancos de dados relacionais SQL, são ideais para aplicações que exigem alta consistência e integridade dos dados, como sistemas financeiros e de contabilidade.
BASE (Basicamente Disponível, Estado Suave, Eventual Consistência):
- Basicamente Disponível: O sistema garante a disponibilidade dos dados, mesmo na presença de falhas, mas pode não garantir a consistência imediata dos dados em todos os nós.
- Estado Suave: O sistema pode estar em um estado de transição por um período, permitindo a eventual consistência dos dados.
- Eventual Consistência: O sistema garante que, eventualmente, todos os nós terão os mesmos dados, mas não garante quando isso ocorrerá. A consistência é alcançada ao longo do tempo.
Os sistemas de banco de dados que seguem o modelo BASE, como muitos bancos de dados NoSQL, são projetados para escalabilidade e flexibilidade, sacrificando a consistência imediata em favor da disponibilidade e da tolerância a partições. Eles são adequados para aplicações que podem tolerar alguma inconsistência temporária, como redes sociais e sistemas de análise de big data.
1.5. Consultas
Os bancos SQL utilizam uma linguagem de consulta estruturada para realizar as consultas aos dados do banco (SQL). A vantagem desse modelo é que não há muita variação entre a performance de cada tipo de consulta. A desvantagem é que, em termos gerais, são consultas que não escalam bem.
Em comparação, os bancos NoSQL variam amplamente no tipo de consulta feita. Basicamente, para cada tipo de banco de dados NoSQL há um tipo de consulta diferente. A vantagem dessa estratégia é poder melhorar a performance, escalabilidade e facilidade de acesso para determinados tipos de consultas. A desvantagem é que consultas que não se adequam ao tipo de banco de dados utilizado podem ter uma perda de performance significativa, tornando-as desvantajosas mesmo em comparação com o SQL.
1.6. Casos de Uso
- SQL: Ideal para aplicações que requerem transações complexas, como sistemas de gerenciamento de relacionamento com o cliente (CRM), sistemas de gerenciamento de recursos empresariais (ERP) e sistemas bancários.
- NoSQL: Adequado para aplicações que lidam com grandes volumes de dados não estruturados ou semi-estruturados, como big data, análise de dados em tempo real, armazenamento de dados de redes sociais e sistemas de recomendação.
3. Tipos de bancos NoSQL
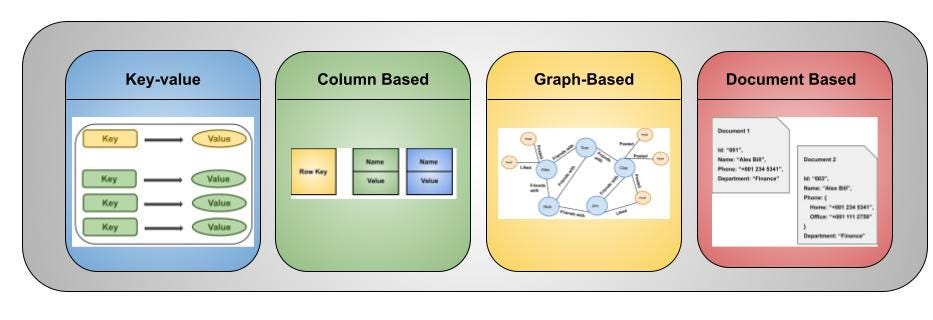
Os bancos de dados NoSQL são projetados para armazenar e gerenciar grandes volumes de dados distribuídos de maneira não relacional. Eles são categorizados em quatro tipos principais: bancos de dados de documentos, chave-valor, colunas e grafos. Cada tipo tem suas próprias características e casos de uso ideais:
3.1. Bancos de Dados de Documentos:
- Exemplo: MongoDB
- Características: Armazenam dados em documentos, geralmente no formato JSON, BSON ou XML. Cada documento pode ter uma estrutura diferente, permitindo flexibilidade na representação de dados.
- Casos de Uso: Aplicações que lidam com dados semiestruturados ou variáveis, como sistemas de gerenciamento de conteúdo, plataformas de e-commerce e aplicações móveis.
3.2. Bancos de Dados Chave-Valor:
- Exemplo: Redis, DynamoDB
- Características: Armazenam dados como pares de chave-valor. Eles são otimizados para operações de leitura e gravação rápidas e são eficientes para armazenar grandes quantidades de dados.
- Casos de Uso: Sessões de usuário, caches, filas de mensagens e configurações de aplicativos.
3.3. Bancos de Dados de Colunas:
- Exemplo: Cassandra, HBase
- Características: Organizam dados em colunas em vez de linhas, o que é eficiente para consultas em grandes conjuntos de dados e para operações de agregação. Eles são projetados para escalabilidade horizontal e desempenho em consultas analíticas.
- Casos de Uso: Sistemas de análise de big data, armazenamento de séries temporais e sistemas de recomendação.
3.4. Bancos de Dados de Grafos:
- Exemplo: Neo4j, ArangoDB
- Características: Armazenam dados como nós e arestas em um grafo, representando entidades e seus relacionamentos. Eles são otimizados para consultas complexas que envolvem relacionamentos entre entidades.
- Casos de Uso: Redes sociais, sistemas de recomendação, análise de fraudes e aplicações de mapeamento de rotas.
Cada tipo de banco de dados NoSQL tem suas próprias vantagens e desvantagens, e a escolha do tipo adequado depende das necessidades específicas da aplicação, da natureza dos dados e dos padrões de acesso.