 RAG
RAG
AutoestudoUma das tarefas mais comuns para se utilizar um LLM é a de "conversar com documentos". No entanto, o modelo com maior capacidade para contexto de prompts se limita a aproximadamente 300 páginas de texto. Para contornar esse problema, precisaremos visitar alguns assuntos relacionados a como carregar, transformar, guardar e buscar textos relevantes ao prompt do nosso usuário.
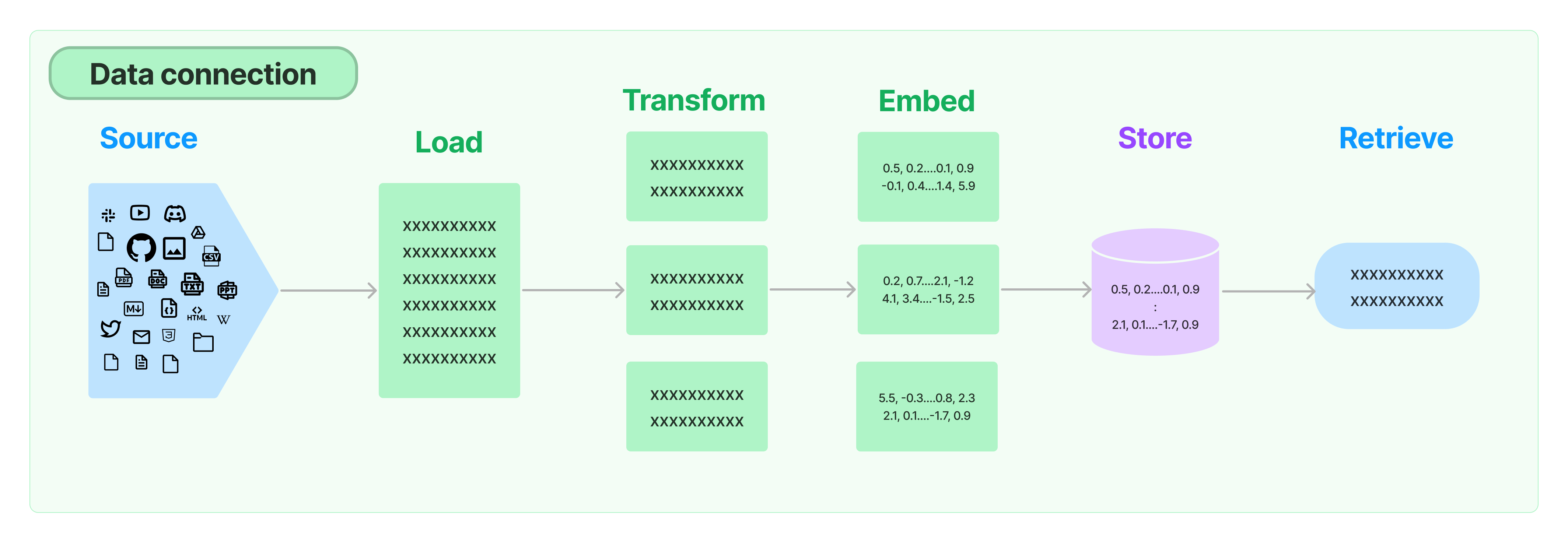 Retirado de langchain
documentation.
Retirado de langchain
documentation.
1. Carregadores e transformadores
Para conseguir utilizar documentos em conjunto com LLMs o que precisamos fazer? Sim! Ler os documentos =)
Para conseguir ler os documentos de diferentes formatos, o Langchain implementa
uma série de
submódulos
com os quais é possível interagir com variados tipos de arquivo (txt, pdf,
artigos do arxiv, repositórios do github). É isso, não tem muito o que
falar aqui. Quer interagir com um tipo de documento específico? Procure pelo
submódulo na documentação do Langchain.
A seguir, precisamos decidir como armazenar o texto. Afinal, não faz sentido
algum simplesmente pegar o texto como um todo e armazenar tudo de uma vez só,
em um único embedding. Sendo assim, temos que decidir como vamos divir o
texto.
AutoestudoAqui vemos que o langchain traz ferramentas para dividir os texto em chunks
com tamanho pré-definidos. Aqui é interessante notar que a decisão de
chunksize e chunk overlap influenciam diretamente na performance da nossa
aplicação com RAG.
2. Vector embeddings
Autoestudo3. Vector storage
AutoestudoAutoestudo4. Exemplos
4.1. RAG simples com FAISS
- OpenAI
- Ollama
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_texts(
["Bread - (0.0, 1.0, 2.0)\nMilk - (1.0, 2.0, 0.0)"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
)
for s in chain.stream("Where is the bread?"):
print(s.content, end="", flush=True)
from langchain.llms import Ollama
from langchain.embeddings import GPT4AllEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_texts(
["Bread - (0.0, 1.0, 2.0)\nMilk - (1.0, 2.0, 0.0)"], embedding=GPT4AllEmbeddings()
)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = Ollama(model="mistral")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
)
for s in chain.stream("Where is the bread?"):
print(s, end="", flush=True)
4.2. RAG usando documento txt c/ ChromaDB
- OpenAI
- Ollama
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.document_loaders import TextLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# load the document and split it into chunks
loader = TextLoader("./data/items.txt")
documents = loader.load()
# split it into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# create the open-source embedding function
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# load it into Chroma
vectorstore = Chroma.from_documents(docs, embedding_function)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI(model="gpt-3.5-turbo")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
)
for s in chain.stream("Where is the bread?"):
print(s.content, end="", flush=True)
from langchain.llms import Ollama
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.document_loaders import TextLoader
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# load the document and split it into chunks
loader = TextLoader("./data/items.txt")
documents = loader.load()
# split it into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# create the open-source embedding function
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# load it into Chroma
vectorstore = Chroma.from_documents(docs, embedding_function)
retriever = vectorstore.as_retriever()
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = Ollama(model="mistral")
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
)
for s in chain.stream("Where is the bread?"):
print(s, end="", flush=True)